One of my long-term projects concerns the relationship between evolution and information. I’m specifically interested in the relationship between mathematical models of evolutionary processes and mathematical measures of information.
As it turns out, there’s an extremely simple link between a minimal model of evolution and a popular measure of information. To explain it, we need to investigate how sequences of numbers grow, and how logarithms relate the rates of growth of different kinds of sequence.
Growing, arithmetically and geometrically
A sequence of numbers grows arithmetically when you add a number to it each time. For example,
$$ 1, 5, 9, 13, … $$
is an arithmetic sequence because it grows by having the number 4 added at each step.
A sequence of numbers grows geometrically when you multiply each element to get the next one. For example,
$$ 1, 4, 16, 64, 256, … $$
is a geometric sequence because it grows by multiplying each element by 4.
Logarithms relate geometric sequences to arithmetic sequences
A logarithm is a mathematical function that turns one number into another number.
$$ \log{8} = 3 $$
There are various ways to characterise what exactly logarithms do. For our purposes, it suffices to say they convert geometric sequences into arithmetic sequences. If you apply a logarithm to every member of a geometric sequence, the result is an arithmetic sequence:
$$
\begin{alignat*}{5}
&\log{1},\ &&\log{4},\ &&\log{16},\ &&\log{64},\ &&\log{256} ,…\\
&\downarrow\ &&\downarrow\ &&\downarrow\ &&\downarrow\ &&\downarrow\\
&0,\ &&2,\ &&4,\ &&6,\ &&8,\ …
\end{alignat*}
$$
Now, some functions are of purely mathematical interest, without application to the real world. Is the logarithm like that? What would it take for logarithms to be not merely a mathematical curiosity, but of genuine scientific interest? If we could find naturally occurring geometric and arithmetic sequences that were associated with each other, the logarithm would represent their association. It would be a bona fide scientific tool.
What kinds of sequence are related to each other? 1. Generations and population size
As it turns out, there are many such sequences. Because we’re interested in evolution, we will investigate one particular relationship between the number of organisms in a lineage and the number of generations over which the lineage has been reproducing.
Take a simple example: a bacterium divides into two identical bacteria every minute. Each descendant, being identical, also divides into two a minute after it was generated. As the number of generations grows arithmetically, the number of bacteria grows geometrically:
$$
\displaylines{
\text{Bacteria: } 1, 2, 4, 8, 16, 32,…\\
\text{Generations: } 0, 1, 2, 3, 4, 5,…
}
$$
The logarithm describes the relationship between the number of bacteria and the number of generations elapsed. It latches onto what we might call the logic of reproduction. Because each copy has the same propensity to produce as many copies as its parent did, the lineage grows exponentially. Just as the logarithm converts geometric sequences into arithmetic sequences, the exponential function – the inverse of the logarithm – converts arithmetic sequences into geometric ones. Reproduction generates an exponential increase in organisms, so logarithms convert numbers of organisms back into numbers of generations:
$$
\begin{alignat*}{8}
&\text{Bacteria: }&& 1,\ && 2,\ && 4,\ && 8,\ && 16,\ && 32,&&…\\
& \mathit{logarithm}\downarrow&&&&&&&&&&&&&& \uparrow\mathit{exponential}\\
&\text{Generations: }&& 0,&& 1,&& 2,&& 3,&& 4,&& 5,&&…
\end{alignat*}
$$
In a slogan, the logic of reproduction is logarithmic.
What kinds of sequence are related to each other? 2. String length and possibilities represented
Another kind of relationship linking a geometric sequence to an arithmetic sequence is a little more abstract. Imagine a string of digits, where each digit can be either 0 or 1. Now think about how many different strings there can be of a particular length.
There are two strings of length one: 0 and 1. There are four strings of length two: 00, 01, 10 and 11. There are eight strings of length three, and so on. Overall, the number of possible strings is logarithmically related to the length of the string:
$$
\begin{alignat*}{7}
&\text{Strings: }&& 2,\ && 4,\ && 8,\ && 16,\ && 32,&&…\\
& \mathit{logarithm}\downarrow&&&&&&&&&&&& \uparrow\mathit{exponential}\\
&\text{Length: }&& 1,&& 2,&& 3,&& 4,&& 5,&&…
\end{alignat*}
$$
This relationship can be depicted in a way that highlights its similarity to the lineage of bifurcating bacteria:
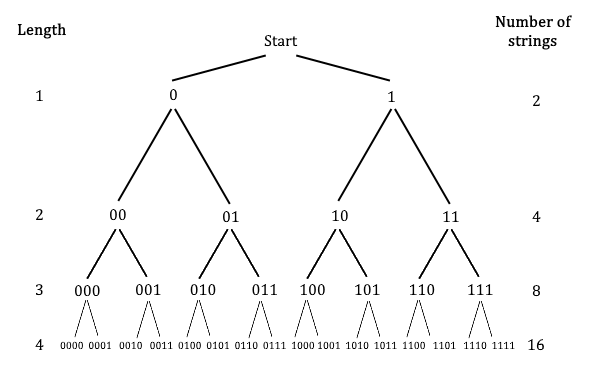
In information theory – and communication theory out of which it grew – such strings are used to represent other things. In the kind of binary code depicted in the figure, strings of 0s and 1s might be used to represent characters of the Latin alphabet (A, B, C…), or numbers, or colours appearing on a screen. To avoid confusion, each character (or number, or colour, or whatever) must be represented with a distinct string. Thus the number of objects that can be represented given a particular length of string is just the number of strings available. And because the number of strings is logarithmically related to the length of the string, the number of representable objects is related in the same way. We might call this the logic of symbolic representation, since digits are a kind of symbol.
In a slogan, the logic of symbolic representation is logarithmic.
The logic of symbolic representation justifies informational measures
Summary so far: because the growth of lineages per generation mirrors the increasing number of distinct strings for each symbol added, both the logic of reproduction and the logic of symbolic representation are logarithmic. To go further, it helps to know why would should care about the relationship between string length and number of objects represented.
Information theory initially emerged from communication theory, where the point of informational measures was to determine how much could be learned from a signal. If we think of a signal as a string of symbols, and we think of “how much can be learned” as “how many objects can be distinguished”, then an appropriate measure of how much can be learned from a signal should be a measure that tells us how many objects a string allows us to distinguish between. This would measure something like the “discrimination power” of a signal.
But the logarithm takes this number (things discriminated) and converts it into a different number (string length). Why? One reason is that communication theory cares about the length of a string as well as how many objects that string allows a receiver to distinguish among. What really matters to communications engineers is the effort required to transmit a signal, and this effort increases as its length increases. The longer the string, the longer time it takes to send, the more costly it is to transmit. Indeed, many of the methods of communication theory are geared towards reducing the lengths of strings that need to be sent. Since length is proportional to cost, trading off cost against discrimination power would benefit from having both concepts translated to a common scale. That’s what the logarithm does.
A second reason becomes apparent when you think about receiving several signals. If one signal allows you to distinguish 8 objects, then two signals of the same length will, in general, allow you to distinguish between 64 objects (depending on details: it may only allow you to distinguish fewer, but it certainly won’t allow you to distinguish more!). Individual signals are like the individual symbols of a string: receiving several of them causes the number of possiblities you can distinguish among to multiply. But what we want – or rather, what introductory textbooks in communication theory tell us we want – is a measure of “discrimination power” that is additive when we add several signals together. We want a measure such that if one signal gives us N units, two signals gives us N+N units. That is also what the logarithm does.
For these reasons it makes sense to use logarithms to quantify the “discrimination power” of signals. We define a standard family of strings – those that contain only the symbols 0 and 1 – and then every kind of signal has its discrimination power quantified by saying what length of standardized string it is equivalent to. Any signal (whether it’s string-like or something completely different) can have its “discrimination power” measured by associating it with the equivalent size of standardized string. That’s the fundamental justification for using logarithms in our measure of what is more commonly called information.
Information and reproduction
The fact that the logic of reproduction and the logic of symbolic representation are both logarithmic suggests that there might be links between the two. But are any of these links theoretically interesting? It’s easy enough to think of a mundane link:
- Q: What length of string would be needed to represent a unique individual in the \(N\)th generation of a lineage?
- A: \(N\).
This might be of interest, say, to a bioinformatician calculating how much disk space is required to store the results of an experiment. But we want something deeper; something that speaks to the widespread suppostion that evolution is itself an information-gathering process. Happily, research on evolution from an informational perspective has suggested intriguing connections.
To take one example, Matina Donaldson-Matasci and colleagues have shown a way to relate the amount of information consumed by an organism to the fitness advantage that information enables. Without going into too much detail, consider an organism able to condition its behaviour on an environmental cue that carries information about fitness-relevant conditions. Since the information in a cue is measured logarithmically, and the change in an organism’s reproductive power due to observing the cue is also measured logarithmically, cues have two logarithmic measures associated with them: one that says “how many situations does this cue allow me to distinguish among?” and another that says “how much better can an organism do by responding to this cue?” Donaldson-Matasci and colleagues show that the first of these measures is an upper bound on the second. Informally, the “discrimination power” of a cue is an upper bound on its “reproductive power”. The authors summarise this idea with a nice quote:
For simplicity, consider an extreme example in which individuals survive only if their phenotype matches the environment exactly, and suppose that there are ten possible environments that occur with equal probability. In the absence of any cue about the environment, the best the organism can do is randomly choose one of the ten possible phenotypes with equal probability. Only one tenth of the individuals will then survive, since only a tenth will match the environment with their phenotype. If a cue conveys 1 bit of information and thus reduces the uncertainty about the environment twofold, the environment can be only in one of five possible states. The organism will now choose randomly one of five possible phenotypes, and now a fifth of the population will survive - a twofold increase in fitness, or a gain of 1 bit in the log of the growth rate. Donaldson-Matasci et al. (2010:228)
More links between evolution and information theory have been proposed and the topic is becoming more popular. Here I outlined the basic mathematical fact I suspect underpins many links of this kind: the logic of reproduction and the logic of symbolic representation are both logarithmic.